






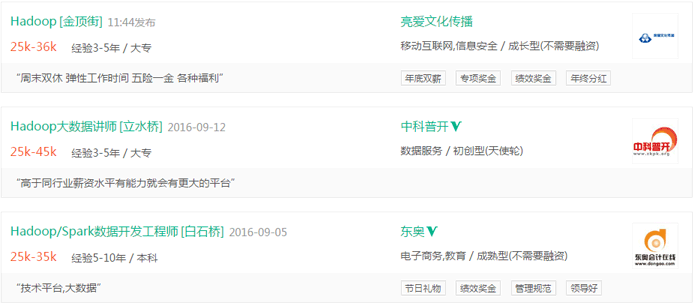
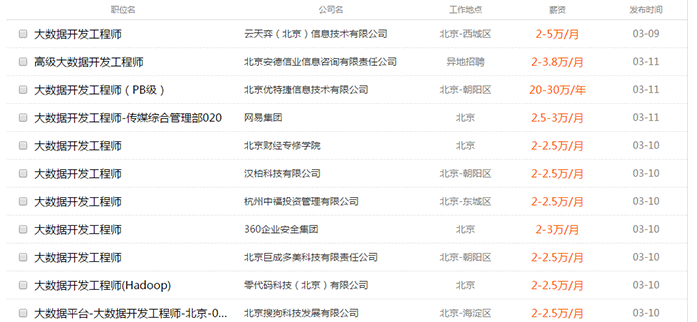



我们为你提供权威的项目实战
大数据时代,为我们开发项目提供了支撑

旅游网站的流式计算应用
Spark 组件的Streaming是一个接近实时的流计算框架。 它允许工程师和数据科学家轻松利用SparkStreaming和SQL来获得实时数据洞察能力并构建实时反馈循环。在其上构建了多个关键任务应用程序。在这次项目中,我们将首先概述SparkStream,然后讨论几个生产用例,例如数据仓库的实时摄取管道,以及计算在线数据产品的派生数据。我们将讨论 Stream如何集成到我们的大数据生态系统,如Kafka,HBase和Hive,并分享一系列的经验教训。其中包括扩展多个Streaming作业,同时使用单个Kafka集群,管理流式作业的生命周期和检查点, 以及将 HBase 用作状态存储的最佳实践。
申请免费试听>>
Hadoop电商精准营销
公司传统业务在MySQL平台,为客户提供360的画像,公司决定利用非结构化数据:网站后天日志分析用户操作行为,为精准营销准备数据。本项目通过传统业务迁移、关联非结构化数据与结构化数据、优化集群到如何利用 Spark 实现精准营销 算法及可视化,为大家总结大数据全知识体系的内容。
申请免费试听>>
互联网搜索公司的多媒体流式处理框架
随着移动时代的到来,来自智能手机用户的大量多媒体文件在网上发布。我们现在迫切需要一个高效的分布式平台来处理和分析这些多媒体数据。然而,现有方法通常遭受与遗留多媒体理解实现的兼容性问题;由于多媒体数据的大文件大小导致的存储器管理问题;和有限平台数据格式支持。通过基于二进制数据管道的执行,提出了基于流的实现,以及灵活的I / O类型以支持各种应用场景。在本项目中我们将演示如何在公司的图像货币化产品中使用这个框架,以加快我们的模型训练流程,并提高我们的CTR预测。
申请免费试听>>